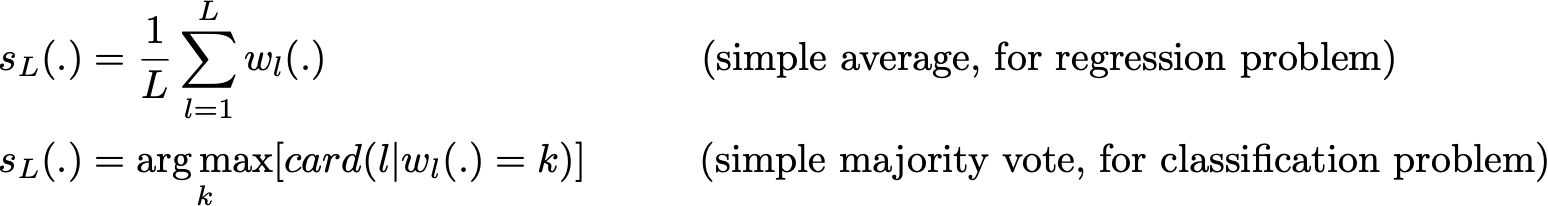“công đoàn là sức mạnh”. Tôi không biết câu này xuất hiện ở đâu và khi nào, nhưng nó khái quát ý tưởng về phương pháp kết hợp trong học máy.
ví dụ: bạn có 1 mô hình nhưng đầu ra của mô hình đó không tốt, vì vậy hãy thử các mô hình khác. sau khi tìm được mô hình ưng ý và “có thể đúng”, bạn cần chỉnh sửa từ thuật toán xuống siêu tham số để có mô hình chính xác nhất. tất cả những điều trên sẽ làm mất nhiều thời gian của bạn vì phải chạy từng mô hình một, vì vậy để nhanh hơn bạn kết hợp các mô hình “học yếu” này lại để tạo thành mô hình “học mạnh hơn”, không những thế kết quả thu được cũng tốt hơn. so với từng mô hình riêng lẻ.
Để hiểu sâu hơn, chúng tôi sẽ làm rõ khái niệm về mô hình “yếu” và “mạnh”.
Khi thực hiện các bài toán phân loại hoặc hồi quy, mọi người đều biết rằng phần quan trọng nhất là lựa chọn mô hình. Việc lựa chọn này phụ thuộc vào nhiều yếu tố: lượng dữ liệu, đặc điểm của dữ liệu (thứ nguyên, phân phối), v.v., từ đó ta sẽ có được mối tương quan giữa dữ liệu và mô hình (bù lệch phương sai) hay còn gọi là (điểm quan hệ) thay đổi giữa độ chệch và phương sai). ok Tôi sẽ không đi chi tiết về khái niệm này vì nó cũng rất mất thời gian, bạn có thể kiểm tra tại đây (https://forum.machinelearningcoban.com/t/moi-quan-he-danh-doi )-gia-bias -va-varianza / 4173.
Nói chung, không có mô hình nào hoàn hảo khi làm việc riêng lẻ do quy tắc đánh đổi ở trên, những mô hình này có những điểm yếu rõ ràng, chẳng hạn như có độ chệch cao (mô hình dự đoán sai nhiều thứ so với giá trị thực) hoặc chúng có phương sai cao (phỏng đoán chính xác trên tập dữ liệu tàu nhưng không đúng với tập dữ liệu không bao giờ tìm thấy), vì vậy tất cả chúng được gọi là “yếu”. vậy tại sao chúng ta không kết hợp các mô hình “yếu” để tạo ra một mô hình “mạnh” đúng với câu nói “3 cây cùng làm nên núi cao” để giảm bớt sự sai lệch hay sai lệch?
nói tóm lại, tôi có một loạt các mô hình “yếu” và tôi muốn kết hợp chúng thành một mô hình “mạnh” hiệu quả hơn. vì vậy tôi phải làm theo các bước sau:
Đầu tiên, chọn mô hình sẽ là mô hình cơ sở cho toàn bộ thuật toán. thường thì một mô hình sẽ được chọn (ví dụ cây quyết định), chúng ta cần rất nhiều mô hình “yếu”, vì vậy chúng tôi cần tăng số lượng mô hình để sử dụng = & gt; chúng ta có n mô hình cây quyết định <- chỉ là các ví dụ. nhưng giống nhau là chưa đủ, những người mẫu này sẽ được đào tạo theo những cách khác nhau. Tất nhiên, cũng có một số phương pháp để lấy các mô hình khác nhau và kết hợp chúng (sẽ nói thêm ở phần sau).
một điểm quan trọng khi chọn mô hình ở đây là chúng tôi phải chọn mô hình phù hợp với chiến lược mà chúng tôi đã chọn ban đầu. Giống như các mô hình có độ chệch thấp nhưng phương sai cao, khi chúng tôi kết hợp chúng để tạo ra một mô hình mạnh hơn, mô hình kết hợp này sẽ có xu hướng giảm phương sai. Không giống như các mô hình có độ chệch cao nhưng phương sai thấp, mô hình kết hợp sẽ có xu hướng giảm độ chệch. điều này dẫn đến câu hỏi về cách kết hợp các mô hình “yếu”.
thứ hai, đây là phần quan trọng: 3. Tôi xin giới thiệu với các bạn 3 biến thể của phương pháp học chung đang được sử dụng rộng rãi hiện nay:
- đóng gói : tạo một số lượng lớn các mô hình (thường cùng loại) trên các mẫu con khác nhau của tập dữ liệu huấn luyện (mẫu ngẫu nhiên trên tập dữ liệu để tạo một tập dữ liệu mới ). các mô hình này sẽ được đào tạo độc lập và song song, nhưng kết quả của chúng sẽ được tính trung bình để có kết quả cuối cùng.
- tăng cường : xây dựng một số lượng lớn các mô hình (thường là cùng một loại ). mỗi mô hình sau sẽ học cách sửa lỗi của mô hình trước (dữ liệu mà mô hình trước đó dự đoán sai) – & gt; tạo thành một chuỗi các mô hình trong đó mô hình tiếp theo sẽ tốt hơn mô hình trước vì trọng số được cập nhật qua từng mô hình (cụ thể, trọng số của dữ liệu dự đoán đúng sẽ không thay đổi, trong khi trọng số của dữ liệu dự đoán sẽ không thay đổi). sai sẽ được tăng dần) & lt; tốt, nó có thể hơi khó hiểu nhưng tôi sẽ giải thích sau & gt ;. chúng tôi sẽ lấy kết quả của mô hình cuối cùng trong loạt mô hình này làm kết quả trả về (vì mô hình cuối cùng sẽ tốt hơn mô hình trước đó, tương tự, mô hình cuối cùng cũng sẽ tốt hơn mô hình đầu tiên).
- stacking : xây dựng một số mô hình (thường là các loại khác nhau) và một siêu mô hình (mô hình người giám sát), đào tạo các mô hình này một cách độc lập, sau đó siêu mô hình học cách kết hợp các kết quả dự đoán của một số mô hình theo cách tốt nhất .
Trong cả 3 biến thể ở trên, việc đóng bao giúp mô hình tổng hợp giảm phương sai. cách tiếp cận tăng và ngăn xếp để giảm độ chệch (cũng giảm phương sai).
Sau đó, tôi sẽ nói chi tiết hơn về việc đóng gói, tăng cường và xếp chồng trong phần tiếp theo.
Một lần nữa, với tính năng đóng gói, chúng tôi xây dựng một số lượng lớn các mô hình (thường là cùng một loại) trên các mẫu con khác nhau của tập dữ liệu đào tạo. Các mô hình này sẽ được đào tạo song song và độc lập, nhưng kết quả đầu ra của chúng sẽ được tính trung bình để có kết quả cuối cùng.
khởi động
Đây là một kỹ thuật thống kê mà từ 1 tập dữ liệu n tạo ra b tập dữ liệu mới (mẫu khởi động) (thường là kích thước của tập dữ liệu gốc). Tôi sẽ không đi sâu vào kỹ thuật này do thời gian có hạn (nói chung là lười biếng). đây là một ví dụ ngắn gọn về kỹ thuật này, được áp dụng trên tập dữ liệu sonar:
bạn có thể kiểm tra thêm (https://towardsdatascience.com/an-introduction-to-the-bootstrap-method-58bcb51b4d60)
đóng túi
Khi huấn luyện một mô hình, bất kể đó là phân loại hay hồi quy, chúng ta phải xác định một hàm nhận đầu vào và trả về đầu ra được xác định bởi kết quả huấn luyện. do đó, với các đầu vào khác nhau, chúng tôi sẽ có nhiều mô hình khác nhau, nhiều hơn hoặc ít hơn.
Ý tưởng về việc đóng gói khá đơn giản: xếp một nhóm mô hình vào các mẫu b bootstrap và lấy trung bình kết quả dự đoán của các mô hình đó để thu được một mô hình có phương sai thấp. nhưng sự phù hợp độc lập của từng mô hình cần rất nhiều dữ liệu, bạn biết dữ liệu đến từ đâu. vì vậy chúng ta phải tạo một tập dữ liệu mới dựa trên tập dữ liệu cũ bằng cách sử dụng kỹ thuật bootstrap. các dữ liệu mới này có phân bố giống nhau và gần như độc lập nên không ảnh hưởng đến kết quả tổng hợp cuối cùng của các mô hình “yếu”, tính trung bình kết quả của các mô hình cơ sở này cũng sẽ làm giảm phương sai. .
sơ đồ toán học:
chúng tôi có l mẫu bootstrap (tương ứng với l tập dữ liệu) có kích thước b.
tương ứng với tập dữ liệu là mô hình “yếu”.
w1 (.), w2 (.), …, wl (.) begin {align} w_1 (.), w_2 (.), …, w_l (.) end {align} w1 (.), W2 (.), …, wl (.)
Kết hợp các mô hình này, chúng tôi nhận được một mô hình mới và mạnh mẽ hơn. đối với các vấn đề khác nhau, chẳng hạn như hồi quy, đầu ra của mô hình “yếu” sẽ được tính trung bình, sẽ là đầu ra của mô hình “mạnh”. để xếp hạng, lớp đầu ra của mỗi mô hình “yếu” sẽ được tính là 1 phiếu bầu và lớp nhận được nhiều phiếu bầu nhất sẽ là đầu ra của mô hình “mạnh” (đây được gọi là phiếu cứng). trong trường hợp mô hình “yếu” dự đoán xác suất của tất cả các lớp, chúng tôi sẽ tính giá trị trung bình của các xác suất của từng lớp rồi lấy xác suất có giá trị lớn nhất (đây được gọi là bỏ phiếu mềm).
Cuối cùng, để tóm tắt lý thuyết và chuyển sang mã, tôi sẽ chỉ ra một trong những lợi ích của việc đóng gói, đó là tính song song. như hình bên dưới, bạn sẽ thấy rằng cốt lõi của việc đóng bao là tất cả các quá trình song song, vì vậy nếu bạn có một máy mạnh, bạn có thể đào tạo song song từng mô hình và cuối cùng là thêm đầu ra của các mô hình này.
mã đóng gói
thật may mắn cho chúng tôi, thư viện sklearn đã hỗ trợ bạn
với tính năng đóng gói để hồi quy:
có đóng bao để phân loại:
rừng ngẫu nhiên
mô hình này
là một ví dụ điển hình về phương pháp đóng bao. Tôi cho rằng bạn đã hiểu khái niệm về khu rừng ngẫu nhiên vì việc giải thích nó cũng mất khá nhiều thời gian (tôi sẽ chỉ tập trung vào tập hợp và các biến thể của nó, vì vậy hãy thông cảm).
rừng ngẫu nhiên là sự kết hợp của một nhóm cây quyết định, khi cây lớn lên, mô hình này sử dụng một thủ thuật khác để tạo dữ liệu: thay vì chỉ lấy mẫu thông qua các quan sát trong tập dữ liệu để tạo mẫu, chúng tôi sẽ lấy mẫu tất cả các tính năng và ngẫu nhiên chỉ chọn 1 tập hợp con để xây dựng cây.
ví dụ
với việc xây dựng dữ liệu rừng ngẫu nhiên, tất cả các cây sẽ không sợ có đầu vào hoặc đầu ra giống nhau từ các cây khác nhau. Một lợi ích khác của thủ thuật này là làm cho cây quyết định hoạt động hiệu quả hơn khi thiếu dữ liệu, tức là các quan sát.
Tôi sẽ kết thúc phần 1 của bài đăng này tại đây, phần 2 sẽ tập trung vào việc tăng và xếp chồng. nếu có bất kỳ sai sót xin vui lòng góp ý. bài viết trên dựa trên sự hiểu biết của mình và có bản dịch mới sau khi tham khảo một số bài báo trên các phương tiện truyền thông, blog, v.v … nếu muốn có cái nhìn tổng quan hơn các bạn tham khảo các link bên dưới. .
nguồn
Cám ơn đã đọc bài viết của tôi. See u again